Линейный коэффициент корреляции
Более совершенным показателем степени тесноты связи является линейный коэффициент корреляции (r ).
При расчете этого показателя учитываются не только знаки отклонений индивидуальных значений признака от средней, но и сама величина таких отклонений, т.е. соответственно для факторного и результативного признаков, величины и . Однако непосредственно сопоставлять между собой полученные абсолютные величины нельзя, так как сами признаки могут быть выражены в разных единицах (как это имеет место в представленном примере), а при наличии одних и тех же единиц измерения средние могут быть различны по величине. В этой связи сравнению могут подлежать отклонения, выраженные в относительных величинах, т.е. в долях среднего квадратического отклонения (их называют нормированными отклонениями). Так, для факторного признака будем иметь совокупность величин , а для результативного .
Полученные нормированные отклонения можно сравнивать между собой. Для того чтобы на основе сопоставления рассчитанных нормированных отклонений получить обобщающую характеристику степени тесноты связи между признаками для всей совокупности, рассчитывают среднее произведение нормированных отклонений. Полученная таким образом средняя и будет являться линейным коэффициентом корреляции r .
 (1.2)
(1.2)
или поскольку s x и s y для данных рядов являются постоянными и могут быть вынесены за скобку, то формула линейного коэффициента корреляции приобретает следующий вид:
 (1.3)
(1.3)
Линейный коэффициент корреляции может принимать любые значения в пределах от –1 до +1. Чем ближе коэффициент корреляции по абсолютной величине к 1, тем теснее связь между признаками. Знак при линейном коэффициенте корреляции указывает на направление связи: прямой зависимости соответствует знак плюс, а обратный зависимости – знак минус.
Если с увеличением значений факторного признака х , результативный признак у имеет тенденцию к увеличению, то величина коэффициента корреляции будет находиться между 0 и 1. Если же с увеличением значений х результативный признак у имеет тенденцию к снижению, коэффициент корреляции может принимать значения в интервале от 0 до –1.
Полученная величина линейного коэффициента корреляции, как и найденный выше коэффициент Фехнера, свидетельствует о возможном наличии достаточно тесной прямой зависимости между затратами на рекламу и количеством туристов, воспользовавшихся услугами фирмы.
Квадрат коэффициента корреляции (r 2) носит название коэффициента детерминации . Для рассматриваемого примера его величина равна 0,6569, а это означает, что 65,69% вариации числа клиентов, воспользовавшихся услугами фирмы, объясняется вариацией затрат фирм на рекламу своих услуг.
Здесь еще раз следует напомнить, что сама по себе величина коэффициента корреляции не является доказательством наличия причинно-следственной связи между исследуемыми признаками, а является оценкой степени взаимной согласованности в изменениях признаков. Установлению причинно-следственной зависимости предшествует анализ качественной природы явлений. Но есть и еще одно обстоятельство, объясняющее формулировку выводов о возможном наличии связи по величине коэффициента корреляции.
Связано это с тем, что оценка степени тесноты связи с помощью коэффициента корреляции производится, как правило, на основе более или менее ограниченной информации об изучаемом явлении. Возникает вопрос, насколько правомерно наше заключение по выборочным данным в отношении действительного наличия корреляционной связи в той генеральной совокупности, из которой была произведена выборка?
Определение корреляции. Когда говорят о корреляции, используют термины корреляционной связи и корреляционной зависимости . Корреляционная связь обозначает согласованные изменения двух признаков и отражает тот факт, что изменчивость одного признака находится в некотором соответствии с изменчивостью другого. Прежде всего, корреляционная связь является стохастической (вероятностной) и не носит функционального характера причинно-следственных зависимостей. В корреляционных связях каждому значению одного признака может соответствовать распределение значений другого признака, но не определенное значение. Например, корреляционная связь признаков может свидетельствовать не о зависимости признаков между собой, а зависимости обоих этих признаков от какого-либо третьего или сочетания признаков, вообще не рассматриваемых в исследовании. Зависимость признаков подразумевает влияние , связь - согласованные изменения , которые могут объясняться целым комплексом причин.
Под корреляцией обычно понимается мера линейной зависимости между случайными переменными, не имеющая строгого функционального характера, при которой изменение одной из случайных величин приводит к изменению математического ожидания другой, т.е. это мера зависимости переменных, показывающая, как изменится математическое ожидание Y при изменении Х .
Числовая характеристика совместного распределения двух случайных величин, выражающая их взаимосвязь, называется коэффициентом корреляции.
Корреляционные связи различаются по форме, направлению и степени . По форме корреляционная связь может быть прямолинейной (шкала MAS Тейлора –шкала нейротизма Айзенка), или криволинейной (между уровнем эффективности решения задачи и мотивацией или тревожностью).
По направлению корреляционная связь может быть положительной (прямой) и отрицательной (обратной).
Степень, сила и теснота корреляционной связи определяется по величине коэффициента корреляции.
Сила связи не зависит от ее направленности и определяется по абсолютному значениюкоэффициента корреляции, принимая значения экстремума функции косинуса (от -1 до +1). Используется две системы классификации оценки силы корреляционной связи.
Общая классификация :
Частная классификация :
Обычно ориентируются на вторую классификацию, учитывающую объем выборки (сильная корреляция может оказаться недостоверной при малых выборках, и достоверной оказаться слабая корреляция при больших выборках, вместе с тем полагают, что сильная корреляция – это не просто корреляция высокого уровня значимости, но и с сильной теснотой связи не ниже 0,70) .
В психологических исследованиях наиболее известна линейная корреляция Пирсона . При вычислении корреляции Пирсона предполагается, что переменные измерены, как минимум, в интервальной шкале. Некоторые другие коэффициенты корреляции могут быть вычислены для менее информативных шкал. Коэффициенты корреляции изменяются в пределах от -1.00 до +1.00. Обратите внимание на крайние значения коэффициента корреляции. Значение -1.00 означает, что переменные имеют строгую отрицательную корреляцию. Значение +1.00 означает, что переменные имеют строгую положительную корреляцию. Отметим, что значение 0.00 означает отсутствие корреляции.
Наиболее часто используемый коэффициент корреляции Пирсона r называется также линейной корреляцией, т.к. измеряет степень линейных связей между переменными.
Простая линейная корреляция (Пирсона r) . Корреляция Пирсона (далее называемая просто корреляцией ) предполагает, что две рассматриваемые переменные измерены, по крайней мере, в интервальной шкале. Она определяет степень, с которой значения двух переменных "пропорциональны" друг другу. Важно, что значение коэффициента корреляции не зависит от масштаба измерения. Например, корреляция между ростом и весом будет одной и той же, независимо от того, проводились измерения в дюймах и футах или в сантиметрах и килограммах . Пропорциональность означает просто линейную зависимость . Корреляция высокая, если на графике зависимость "можно представить" прямой линией (с положительным или отрицательным углом наклона).
Проведенная прямая называется прямой регрессии или прямой, построенной методом наименьших квадратов . Последний термин связан с тем, что сумма квадратов расстояний (вычисленных по оси Y) от наблюдаемых точек до прямой является минимальной. Заметим, что использование квадратов расстояний приводит к тому, что оценки параметров прямой сильно реагируют на выбросы.
Как интерпретировать значения корреляций. Коэффициент корреляции Пирсона (r ) представляет собой меру линейной зависимости двух переменных. Если возвести его в квадрат, то полученное значение коэффициента детерминации r 2) представляет долю вариации, общую для двух переменных (иными словами, "степень" зависимости или связанности двух переменных). Чтобы оценить зависимость между переменными, нужно знать как "величину" корреляции, так и ее значимость .
Значимость корреляций . Возникает закономерный вопрос, почему более сильные зависимости между переменными являются более значимыми? Если предполагать отсутствие зависимости между соответствующими переменными в популяции, то наиболее вероятно ожидать, что в исследуемой выборке связь между этими переменными также будет отсутствовать. Таким образом, чем более сильная зависимость обнаружена в выборке, тем менее вероятно, что этой зависимости нет в популяции, из которой она извлечена. Величина зависимости и значимость тесно связаны между собой, и можно было бы попытаться вывести значимость из величины зависимости и наоборот. Однако указанная связь между зависимостью и значимостью имеет место только при фиксированном объеме выборки, поскольку при различных объемах выборки одна и та же зависимость может оказаться как высоко значимой, так и незначимой вовсе.
Уровень значимости, вычисленный для каждой корреляции, представляет собой главный источник информации о надежности корреляции. Значимость определенного коэффициента корреляции зависит от объема выборок. Критерий значимости основывается на предположении, что распределение остатков (т.е. отклонений наблюдений от регрессионной прямой) для зависимой переменной y является нормальным (с постоянной дисперсией для всех значений независимой переменной x ). Исследования методом Монте-Карло показали, что нарушение этих условий не является абсолютно критичным, если размеры выборки не слишком малы, а отклонения от нормальности не очень большие. Тем не менее, имеется несколько серьезных опасностей, о которых следует знать.
Выбросы . По определению, выбросы являются нетипичными, резко выделяющимися наблюдениями. Так как при построении прямой регрессии используется сумма квадратов расстояний наблюдаемых точек до прямой, то выбросы могут существенно повлиять на наклон прямой и, следовательно, на значение коэффициента корреляции. Поэтому единичный выброс (значение которого возводится в квадрат) способен существенно изменить наклон прямой и, следовательно, значение корреляции.
Заметим, что если размер выборки относительно мал, то добавление или исключение некоторых данных (которые, возможно, не являются "выбросами", как в предыдущем примере) способно оказать существенное влияние на прямую регрессии (и коэффициент корреляции). Это показано в следующем примере, где мы назвали исключенные точки "выбросами"; хотя, возможно, они являются не выбросами, а экстремальными значениями.
Обычно считается, что выбросы представляют собой случайную ошибку, которую следует контролировать. К сожалению, не существует общепринятого метода автоматического удаления выбросов. Чтобы не быть введенными в заблуждение полученными значениями, необходимо проверить на диаграмме рассеяния каждый важный случай значимой корреляции. Очевидно, выбросы могут не только искусственно увеличить значение коэффициента корреляции, но также реально уменьшить существующую корреляцию.
Количественный подход к выбросам. Некоторые исследователи применяют численные методы удаления выбросов. Например, исключаются значения, которые выходят за границы ±2 стандартных отклонений (и даже ±1.5 стандартных отклонений) вокруг выборочного среднего. В ряде случаев такая "чистка" данных абсолютно необходима. Например, при изучении реакции в когнитивной психологии, даже если почти все значения экспериментальных данных лежат в диапазоне 300-700 миллисекунд , то несколько "странных времен реакции" 10-15 секунд совершенно меняют общую картину. К сожалению, в общем случае, определение выбросов субъективно, и решение должно приниматься индивидуально в каждом эксперименте (с учетом особенностей эксперимента или "сложившейся практики" в данной области). Следует заметить, что в некоторых случаях относительная частота выбросов к численности групп может быть исследована и разумно проинтерпретирована с точки зрения самой организации эксперимента.
Корреляции в неоднородных группах. Отсутствие однородности в выборке также является фактором, смещающим (в ту или иную сторону) выборочную корреляцию. Представьте ситуацию, когда коэффициент корреляции вычислен по данным, которые поступили из двух различных экспериментальных групп, что, однако, было проигнорировано при вычислениях. Далее, пусть действия экспериментатора в одной из групп увеличивают значения обеих коррелированных величин, и, таким образом, данные каждой группы сильно различаются на диаграмме рассеяния (как показано ниже на графике).
В подобных ситуациях высокая корреляция может быть следствием разбиения данных на две группы, а вовсе не отражать "истинную" зависимость между двумя переменными, которая может практически отсутствовать (это можно заметить, взглянув на каждую группу отдельно, см. следующий график).
Если вы допускаете такое явление и знаете, как определить "подмножества" данных, попытайтесь вычислить корреляции отдельно для каждого множества. Если вам неясно, как определить подмножества, попытайтесь применить многомерные методы разведочного анализа.
Нелинейные зависимости между переменными. Другим возможным источником трудностей, связанным с линейной корреляцией Пирсона r , является форма зависимости. Корреляция Пирсона r хорошо подходит для описания линейной зависимости. Отклонения от линейности увеличивают общую сумму квадратов расстояний от регрессионной прямой, даже если она представляет "истинные" и очень тесные связи между переменными. Итак, еще одной причиной, вызывающей необходимость рассмотрения диаграммы рассеяния для каждого коэффициента корреляции, является нелинейность. Например, следующий график показывает сильную корреляцию между двумя переменными, которую невозможно хорошо описать с помощью линейной функции.
Измерение нелинейных зависимостей. Что делать, если корреляция сильная, однако зависимость явно нелинейная? К сожалению, не существует простого ответа на данный вопрос, так как не имеется естественного обобщения коэффициента корреляции Пирсона r на случай нелинейных зависимостей. Однако, если кривая монотонна (монотонно возрастает или, напротив, монотонно убывает), то можно преобразовать одну или обе переменные, чтобы сделать зависимость линейной, а затем уже вычислить корреляцию между преобразованными величинами. Для этого часто используется логарифмическое преобразование. Другой подход состоит в использовании непараметрической корреляции (например, корреляции Спирмена ). Иногда этот метод приводит к успеху, хотя непараметрические корреляции чувствительны только к упорядоченным значениям переменных, например, по определению, они пренебрегают монотонными преобразованиями данных. К сожалению, два самых точных метода исследования нелинейных зависимостей непросты и требуют хорошего навыка "экспериментирования" с данными. Эти методы состоят в следующем:
Нужно попытаться найти функцию, которая наилучшим способом описывает данные. После того, как вы определили функцию, можно проверить ее "степень согласия" с данными.
Вы можете иметь дело с данными, разбитыми некоторой переменной на группы (например, на 4 или 5 групп). Определите эту переменную как группирующую переменную, а затем примените дисперсионный анализ.
Разведочный анализ корреляционных матриц. Во многих исследованиях первый шаг анализа состоит в вычислении корреляционной матрицы всех переменных и проверке значимых (ожидаемых и неожиданных) корреляций. После того как это сделано, следует понять общую природу обнаруженной статистической значимости. Иными словами, понять, почему одни коэффициенты корреляции значимы, а другие нет. Однако следует иметь в виду, если используется несколько критериев, значимые результаты могут появляться "удивительно часто", и это будет происходить чисто случайным образом. Например, коэффициент, значимый на уровне.05, будет встречаться чисто случайно один раз в каждом из 20 подвергнутых исследованию коэффициентов. Нет способа автоматически выделить "истинную" корреляцию. Поэтому следует подходить с осторожностью ко всем не предсказанным или заранее не запланированным результатам и попытаться соотнести их с другими (надежными) результатами. В конечном счете, самый убедительный способ проверки состоит в проведении повторного экспериментального исследования. Такое положение является общим для всех методов анализа, использующих "множественные сравнения и статистическую значимость".
Построчное удаление пропущенных данных в сравнении с попарным удалением. Принятый по умолчанию способ удаления пропущенных данных при вычислении корреляционной матрицы - состоит в построчном удалении наблюдений с пропусками (удаляется вся строка, в которой имеется хотя бы одно пропущенное значение). Этот способ приводит к "правильной" корреляционной матрице в том смысле, что все коэффициенты вычислены по одному и тому же множеству наблюдений. Однако если пропущенные значения распределены случайным образом в переменных, то данный метод может привести к тому, что в рассматриваемом множестве данных не останется ни одного неисключенного наблюдения (в каждой строке наблюдений встретится, по крайней мере, одно пропущенное значение). Чтобы избежать подобной ситуации, используют другой способ, называемый попарным удалением . В этом способе учитываются только пропуски в каждой выбранной паре переменных и игнорируются пропуски в других переменных. Корреляция между парой переменных вычисляется по наблюдениям, где нет пропусков. Во многих ситуациях, особенно когда число пропусков относительно мало, скажем 10%, и пропуски распределены достаточно хаотично, этот метод не приводит к серьезным ошибкам. Однако, иногда это не так.
Например, в систематическом смещении (сдвиге) оценки может "скрываться" систематическое расположение пропусков, являющееся причиной различия коэффициентов корреляции, построенных по разным подмножествам. Другая проблема связанная с корреляционной матрицей, вычисленной при попарном удалении пропусков, возникает при использовании этой матрицы в других видах анализа (например, Множественная регрессия , Факторный анализ или Кластерный анализ ). В них предполагается, что используется "правильная" корреляционная матрица с определенным уровнем состоятельности и "соответствия" различных коэффициентов. Использование матрицы с "плохими" (смещенными) оценками приводит к тому, что программа либо не в состоянии анализировать такую матрицу, либо результаты будут ошибочными. Поэтому, если применяется попарный метод исключения пропущенных данных, необходимо проверить, имеются или нет систематические закономерности в распределении пропусков.
Как определить смещения, вызванные попарным удалением пропущенных данных. Если попарное исключение пропущенных данных не приводит к какому-либо систематическому сдвигу в оценках, то все эти статистики будут похожи на аналогичные статистики, вычисленные при построчном способе удаления пропусков. Если наблюдается значительное различие, то есть основание предполагать наличие сдвига в оценках. Например, если среднее (или стандартное отклонение) значений переменной A, которое использовалось при вычислении ее корреляции с переменной B, много меньше среднего (или стандартного отклонения) тех же значений переменной A, которые использовались при вычислении ее корреляции с переменной C, то имеются все основания ожидать, что эти две корреляции (A-B и A-C) основаны на разных подмножествах данных, и, таким образом, в оценках корреляций имеется сдвиг, вызванный неслучайным расположением пропусков в значениях переменных.
Попарное удаление пропущенных данных в сравнении с подстановкой среднего значения. Другим общим методом, позволяющим избежать потери наблюдений при построчном способе удаления наблюдений с пропусками, является замена средним (для каждой переменной пропущенные значения заменяются средним значением этой переменной). Подстановка среднего вместо пропусков имеет свои преимущества и недостатки в сравнении с попарным способом удаления пропусков. Основное преимущество в том, что он дает состоятельные оценки, однако имеет следующие недостатки:
Подстановка среднегоискусственно уменьшает разброс данных, иными словами, чем больше пропусков, тем больше данных, совпадающих со средним значением, искусственно добавленным в данные.
Так как пропущенные данные заменяются искусственно созданными "средними", то корреляции могут сильно уменьшиться.
Ложные корреляции . Основываясь на коэффициентах корреляции, вы не можете строго доказать причинной зависимости между переменными, однако можете определить ложные корреляции, т.е. корреляции, которые обусловлены влияниями "других", остающихся вне вашего поля зрения переменных. Лучше всего понять ложные корреляции на простом примере. Известно, что существует корреляция между ущербом, причиненным пожаром, и числом пожарных, тушивших пожар. Однако эта корреляция ничего не говорит о том, насколько уменьшатся потери, если будет вызвано меньше число пожарных. Причина в том, что имеется третья переменная (начальный размер пожара), которая влияет как на причиненный ущерб, так и на число вызванных пожарных. Если вы будете "контролировать" эту переменную (например, рассматривать только пожары определенной величины), то исходная корреляция (между ущербом и числом пожарных) либо исчезнет, либо, возможно, даже изменит свой знак. Основная проблема ложной корреляции состоит в том, что вы не знаете, кто является ее агентом. Тем не менее, если вы знаете, где искать, то можно воспользоваться частные корреляции, чтобы контролировать (частично исключенное ) влияние определенных переменных.
Являются ли коэффициенты корреляции "аддитивными"? Нет, не являются. Например, усредненный коэффициент корреляции, вычисленный по нескольким выборкам, не совпадает со "средней корреляцией" во всех этих выборках. Причина в том, что коэффициент корреляции не является линейной функцией величины зависимости между переменными. Коэффициенты корреляции не могут быть просто усреднены. Если вас интересует средний коэффициент корреляции, следует преобразовать коэффициенты корреляции в такую меру зависимости, которая будет аддитивной. Например, до того, как усреднить коэффициенты корреляции, их можно возвести в квадрат, получить коэффициенты детерминации , которые уже будут аддитивными, или преобразовать корреляции в z значения Фишера , которые также аддитивны.
Как определить, являются ли два коэффициента корреляции значимо различными . Имеется критерий, позволяющий оценить значимость различия двух коэффициентов корреляциями. Результат применения критерия зависит не только от величины разности этих коэффициентов, но и от объема выборок и величины самих этих коэффициентов. В соответствии с ранее обсуждаемыми принципами, чем больше объем выборки, тем меньший эффект мы можем значимо обнаружить. Вообще говоря, в соответствии с общим принципом, надежность коэффициента корреляции увеличивается с увеличением его абсолютного значения, относительно малые различия между большими коэффициентами могут быть значимыми.
При расчете этого показателя учитываются величины отклонений индивидуальных значений признака от средней, т.е. соответственно для факторного и результативного признаков величины .
Однако непосредственно сопоставлять между собой данные абсолютные величины нельзя. Признаки могут быть выражены в разных единицах, а при одинаковых единицах измерения средние могут быть различны по величине. Сравнению подлежат отклонения, выраженные в долях среднего квадратического отклонения (нормированные отклонения).
Рассчитывают среднее произведение нормированных отклонений, которое называется линейным коэффициентом корреляции :
Выполнив несложные преобразования, можно получить следующую формулу для расчета линейного коэффициента корреляции:

При пользовании этой формулой отпадает необходимость вычислять отклонения индивидуальных значений признаков от средней величины, что исключает ошибку в расчетах при округлении средних величин.
Линейный коэффициент корреляции может принимать любые значения в пределах от -1 до + 1 . Чем ближе коэффициент корреляции по абсолютной величине к 1, тем теснее связь между признаками. Знак при линейном коэффициенте корреляции указывает на направление связи. Прямой зависимости соответствует знак плюс, а обратной зависимости - знак минус. Линейный коэффициент корреляции применяется для измерения тесноты связи только при линейной форме связи .
Равенство говорит лишь об отсутствии линейной корреляционной зависимости, но не вообще об отсутствии корреляционной, а тем более статистической зависимости. Величина коэффициента корреляции не является доказательством наличия причинно-следственной связи между исследуемыми признаками, а является оценкой степени взаимной согласованности в изменениях признаков. Установлению причинно-следственной зависимости предшествует анализ качественной природы явлений. Особенно осторожно следует подходить к истолкованию полученных коэффициентов корреляции при незначительных объемах выборочной совокупности.
Пусть по результатам выборочного наблюдения . Объясняется ли это действительно существующей корреляционной связью между признаками в генеральной совокупности или является следствием случайности отбора элементов в выборку?
По вычисленному значению выборочного коэффициента корреляции требуется проверить гипотезу
Н 0: коэффициент корреляции в генеральной совокупности равен нулю при альтернативе
Н 1: коэффициент корреляции в генеральной совокупности не равен нулю.
В качестве статистического критерия для гипотезы Н 0 обычно используется величина
![]()
которая распределена по закону Стьюдента с степенями свободы. Гипотеза Н 0 отвергается (т.е. зависимость считается установленной), если превысит допустимое значение при уровне значимости и степенями свободы. Некоторые значения критерия приведены ниже в таблице.
Таблица 11.
Допустимые значения критерия Стьюдента при числе степеней свободы и уровне значимости .
| 0,05 | 0,01 | |
| 2,10 | 2,88 | |
| 2,09 | 2,86 | |
| 2,09 | 2,85 | |
| 2,08 | 2,83 | |
| 2,07 | 2,82 | |
| 2,07 | 2,81 | |
| 2,06 | 2,80 | |
| 2,06 | 2,79 | |
| 2,06 | 2,78 | |
| 2,05 | 2,77 | |
| 2,05 | 2,76 | |
| 2,05 | 2,76 | |
| 2,04 | 2,75 | |
| 2,02 | 2,70 | |
| 2,00 | 2,66 | |
| 1,98 | 2,62 | |
| 1,96 | 2,58 |
Коэффициент корреляции достаточно точно оценивает степень тесноты связи лишь в случае линейной зависимости между признаками. При криволинейной зависимости линейный коэффициент корреляции недооценивает степень тесноты связи и даже может быть равен 0, а потому в таких случаях рекомендуется использовать в качестве показателя степени тесноты связи другие величины. Рассмотрим эмпирическое корреляционное отношение .
Согласно правилу сложения дисперсий, общая дисперсия равна сумме средней из групповых и межгрупповой
Или ![]()
Корреляционное отношение равно нулю, когда нет колеблемости в величине средних значений результативного признака по выделенным группам. В тех случаях, когда средняя из групповых дисперсий близка к нулю, т.е. практически вся вариация результативного признака обусловлена действием фактора , величина корреляционного отношения близка к 1. Направление связи мы легко установим по данным групповой таблицы (см. пример 9).
Различные экономические явления как на микро-, так и на макроуровне не являются независимыми, а связаны между собой (цена товара и спрос на него, объём производства и прибыль фирмы и.т.д.).
Эта зависимость может быть строго функциональной (детермированной) и статистической.
Зависимость
между
и называетсяфункциональной,
когда
каждому значению одного признака
соответствует одно единственное значение
другого признака. (Примером такой
однозначной зависимости может служить
зависимость площади круга от радиуса).
называетсяфункциональной,
когда
каждому значению одного признака
соответствует одно единственное значение
другого признака. (Примером такой
однозначной зависимости может служить
зависимость площади круга от радиуса).
В реальной действительности чаще встречается иная связь между явлениями, когда каждому значению одного признака могут соответствовать несколько значений другого (например, связь между возрастом детей и их ростом).
Форма связи, при которой один или несколько взаимосвязанных показателей (факторов) оказывают влияние на другой показатель (результат) не однозначно, а с определенной долей вероятности, называется статистической . В частности, если при изменении одной из величин изменяется среднее значение другой, то в этом случае статистическую зависимость называют корреляционной .
В зависимости от числа факторов, включаемых в модель, различают парную корреляцию (связь двух переменных) и множественную (зависимость результата от нескольких факторов).
Корреляционный
анализ
состоит в определении направления,
формы и степени
связи (тесноты) между двумя (несколькими)
случайными признаками
 и
и .
.
По направлению корреляция бывает положительной (прямой) , если при увеличении значений одной переменной увеличивается значение другой, и отрицательной (обратной) , если при увеличении значений одной переменной, уменьшается значение другой.
По
форме
корреляционная связь может быть линейной
(прямолинейной)
,
когда изменение значений одного признака
приводит к равномерному изменению
другого (математически описывается
уравнением прямой
 ),
икриволинейной
,
когда изменение значений одного признака
приводит к неодинаковым изменениям
другого (математически она описывается
уравнениями кривых линий, например
гиперболы
),
икриволинейной
,
когда изменение значений одного признака
приводит к неодинаковым изменениям
другого (математически она описывается
уравнениями кривых линий, например
гиперболы
 ,
параболы
,
параболы и т.д.).
и т.д.).
Простейшей формой зависимости между переменными является линейная зависимость. И проверка наличия такой зависимости, оценивание её индикаторов и параметров является одним из важнейших направлений эконометрики.
Существуют специальные статистические методы и, соответственно, показатели, значения которых определённым образом свидетельствуют о наличии или отсутствии линейной связи между переменными.
3.1. Коэффициент линейной корреляции
Наиболее простым, приближенным способом выявления корреляционной связи является графический .
При
небольшом объеме выборки экспериментальные
данные представляют в виде двух рядов
связанных между собой значений
 и
и .
Если каждую пару
.
Если каждую пару представить точкой на плоскости
представить точкой на плоскости ,
то получится так называемоекорреляционное
поле (рис.1).
,
то получится так называемоекорреляционное
поле (рис.1).
Если корреляционное поле представляет собой эллипс, ось которого расположена слева направо и снизу вверх (рис.1в), то можно полагать, что между признаками существует линейная положительная связь.
Если корреляционное поле вытянуто вдоль оси слева направо и сверху вниз (рис.1г), то можно полагать наличие линейной отрицательной связи.
В случае же если точки наблюдений располагаются на плоскости хаотично, т.е корреляционное поле образует круг (рис.1а), то это свидетельствует об отсутствии связи между признаками.
На рис.1б представлена строгая линейная функциональная связь.
Под
теснотой
связи между двумя величинами понимают
степень сопряженности между ними,
которая обнаруживается с изменением
изучаемых величин. Если каждому заданному
значению
 соответствуют близкие друг другу
значения
соответствуют близкие друг другу
значения ,
то связь считается тесной (сильной);
если же значения
,
то связь считается тесной (сильной);
если же значения сильно разбросаны, то связь считается
менее тесной. При тесной корреляционной
связи корреляционное поле представляет
собой более или менее сжатый эллипс.
сильно разбросаны, то связь считается
менее тесной. При тесной корреляционной
связи корреляционное поле представляет
собой более или менее сжатый эллипс.
Количественным критерием направления и тесноты линейной связи является коэффициент линейной корреляции .
Коэффициент корреляции, определяемый по выборочным данным, называется выборочным коэффициентом корреляции. Онвычисляется по формуле:

где
 ,
,
текущие значения признаков
текущие значения признаков
 и
и ;
; и
и
средние арифметические значения
признаков;
средние арифметические значения
признаков;
 - среднее арифметическое произведений
вариант,
- среднее арифметическое произведений
вариант, и
и
средние квадратические отклонения этих
признаков;
средние квадратические отклонения этих
признаков;

объём выборки.
объём выборки.
|
|

Для вычисления коэффициента корреляции достаточно принять предположение о линейной связи между случайными признаками. Тогда вычисленный коэффициент корреляции и будет мерой этой линейной связи.
Коэффициент
линейной корреляции принимает значения
от −1 в случае строгой линейной
отрицательной связи, до +1 в случае
строгой линейной положительной связи
(т.е.
 ).
Близость коэффициента корреляции к 0
свидетельствует об отсутствиилинейной
связи между признаками, но не об отсутствии
связи между ними вообще.
).
Близость коэффициента корреляции к 0
свидетельствует об отсутствиилинейной
связи между признаками, но не об отсутствии
связи между ними вообще.
Коэффициенту корреляции можно дать наглядную графическую интерпретацию.
Если
 ,
то между признаками существует линейная
функциональная зависимость вида
,
то между признаками существует линейная
функциональная зависимость вида ,
что означаетполную
корреляцию
признаков. При
,
что означаетполную
корреляцию
признаков. При
 ,
прямая имеет положительный наклон по
отношению к оси
,
прямая имеет положительный наклон по
отношению к оси ,
при
,
при
отрицательный (рис. 1б).
отрицательный (рис. 1б).
Если
 ,
точки
,
точки находятся в области ограниченной линией,
напоминающей эллипс. Чем ближе коэффициент
корреляции к
находятся в области ограниченной линией,
напоминающей эллипс. Чем ближе коэффициент
корреляции к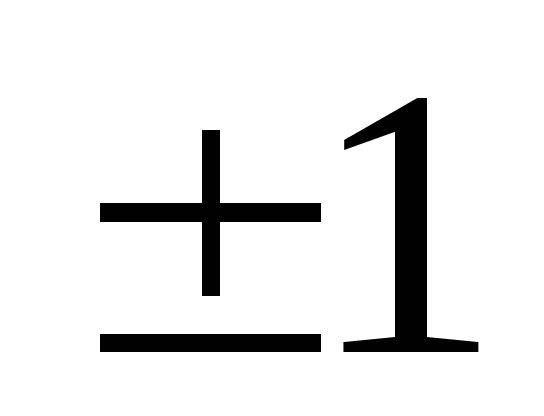 ,
тем уже эллипс и тем теснее точки
сосредоточены вблизи прямой линии. При
,
тем уже эллипс и тем теснее точки
сосредоточены вблизи прямой линии. При говорят оположительной
корреляции
.
В этом случае значения
говорят оположительной
корреляции
.
В этом случае значения
 имеют тенденцию к возрастанию с
увеличением
имеют тенденцию к возрастанию с
увеличением (рис.1в). При
(рис.1в). При говорят оботрицательной
корреляции
;
значения
говорят оботрицательной
корреляции
;
значения
 имеют тенденцию к уменьшению с ростом
имеют тенденцию к уменьшению с ростом (рис.1г).
(рис.1г).
Если
 ,
то точки
,
то точки располагаются в области, ограниченной
окружностью. Это означает, что между
случайными признаками
располагаются в области, ограниченной
окружностью. Это означает, что между
случайными признаками и
и отсутствует корреляция, и такие признаки
называютсянекоррелированными
(рис.1а).
отсутствует корреляция, и такие признаки
называютсянекоррелированными
(рис.1а).
При оценке тесноты связи можно использовать следующую условную таблицу:
|
Теснота связи |
Величина коэффициента корреляции при наличии |
|
|
прямой связи (+) |
обратной связи (−) |
|
|
Связь отсутствует |
|
|
|
Связь слабая |
|
|
|
Связь умеренная |
|
|
|
Связь сильная |
|
|
|
Полная функциональная |
|
|










Заметим,
что в числителе формулы для выборочного
коэффициента линейной корреляции
величин
 и
и с
тоит ихпоказатель
ковариации
:
с
тоит ихпоказатель
ковариации
:

Этот
показатель, как и коэффициент корреляции
характеризует степень линейной связи
величин
 и
и .
Если он больше нуля, то связь между
величинами положительная, если меньше
нуля, то связь – отрицательная, равен
нулю – линейная связь отсутствует.
.
Если он больше нуля, то связь между
величинами положительная, если меньше
нуля, то связь – отрицательная, равен
нулю – линейная связь отсутствует.
В
отличие от коэффициента корреляции
показатель ковариации нормирован – он
имеет размерность, и его величина зависит
от единиц измерения
 и
и .
В статистическом анализе показатель
ковариации обычно используется, как
промежуточный элемент расчёта коэффициента
линейной корреляции. Т.о. формула расчёта
выборочного коэффициента корреляции
приобретает вид:
.
В статистическом анализе показатель
ковариации обычно используется, как
промежуточный элемент расчёта коэффициента
линейной корреляции. Т.о. формула расчёта
выборочного коэффициента корреляции
приобретает вид:

Экономические данные представляют собой количественные характеристики каких-либо экономических объектов или процессов. Они формируются под действием множества факторов, не все из которых доступны внешнему контролю. Неконтролируемые факторы могут принимать случайные значения из некоторого множества значений и тем самым обусловливать случайность данных, которые они определяют. Одной из основных задач в экономических исследованиях является анализ зависимостей между переменными.
Рассматривая зависимости между признаками, необходимо выделить прежде всего два типа связей:
- функциональные - характеризуются полным соответствием между изменением факторного признака и изменением результативной величины: каждому значению признака-фактора соответствуют вполне определенные значения результативного признака. Этот тип связи выражается в виде формульной зависимости. Функциональная зависимость может связывать результативный признак с одним или несколькими факторными признаками. Так, величина заработной платы при повременной оплате труда зависит от количества отработанных часов;
- корреляционные - между изменением двух признаков нет полного соответствия, воздействие отдельных факторов проявляется лишь в среднем, при массовом наблюдении фактических данных. Одновременное воздействие на изучаемый признак большого количества разнообразных факторов приводит к тому, что одному и тому же значению признака-фактора соответствует целое распределение значений результативного признака, поскольку в каждом конкретном случае прочие факторные признаки могут изменять силу и направленность своего воздействия.
Следует иметь в виду, что при наличии функциональной зависимости между признаками можно, зная величину факторного признака, точно определить величину результативного признака. При наличии же корреляционной зависимости устанавливается лишь тенденция изменения результативного признака при изменении величины факторного признака.
Изучая взаимосвязи между признаками, их классифицируют по направлению, форме, числу факторов:
- по направлению связи делятся на прямые и обратные. При прямой связи направление изменения результативного признака совпадает с направлением изменения признака-фактора. При обратной связи направление изменения результативного признака противоположно направлению изменения признака- фактора. Например, чем выше квалификация рабочего, тем выше уровень производительности его труда (прямая связь). Чем выше производительность труда, тем ниже себестоимость единицы продукции (обратная связь);
- по форме (виду функции) связи делят на линейные (прямолинейные) и нелинейные (криволинейные). Линейная связь отображается прямой линией, нелинейная - кривой (парабол ой, гиперболой и т.п.). При линейной связи с возрастанием значения факторного признака происходит равномерное возрастание (убывание) значения результативного признака;
- по количеству факторов, действующих на результативный признак, связи подразделяют на однофакторные (парные) и многофакторные.
Изучение зависимости вариации признака от окружающих условий и составляет содержание теории корреляции .
При проведении корреляционного анализа вся совокупность данных рассматривается как множество переменных (факторов), каждая из которых содержит п наблюдений.
При изучении взаимосвязи между двумя факторами их, как правило, обозначают Х= (х р х 2 , ...,х п) и Y= (у { , у 2 , ...,у и).
Ковариация - это статистическая мера взаимодействия двух переменных. Например, положительное значение ковариации доходности двух ценных бумаг показывает, что доходности этих ценных бумаг имеют тенденцию изменяться в одну сторону.
Ковариация между двумя переменными X и Y рассчитывается следующим образом:
где- фактические значения переменных
X
и г;

Если случайные величины Хи Y независимы, теоретическая ковариация равна нулю.
Ковариация зависит от единиц, в которых измеряются переменные Хи У, она является ненормированной величиной. Поэтому для измерения силы связи между двумя переменными используется другая статистическая характеристика, называемая коэффициентом корреляции.
Для двух переменных X и Y коэффициент парной корреляции
определяется следующим образом:

где SSy - оценки дисперсий величин Хи Y. Эти оценки характеризуют степень разброса значений х { ,х 2 , ...,х п (у 1 ,у 2 ,у п) вокруг своего среднего х (у соответственно), или вариабельность (изменчивость) этих переменных на множестве наблюдений.
Дисперсия (оценка дисперсии) определяется по формуле

В общем случае для получения несмещенной оценки дисперсии сумму квадратов следует делить на число степеней свободы оценки (п-р), где п - объем выборки, р - число наложенных на выборку связей. Так как выборка уже использовалась один раз для определения среднего X, то число наложенных связей в данном случае равно единице (р = 1), а число степеней свободы оценки (т.е. число независимых элементов выборки) равно (п - 1).
Более естественно измерять степень разброса значений переменных в тех же единицах, в которых измеряется и сама переменная. Эту задачу решает показатель, называемый среднеквадратическим отклонением
(стандартным отклонением
) или стандартной ошибкой
переменной X
(переменной Y)
и определяемый соотношением

Слагаемые в числителе формулы (3.2.1) выражают взаимодействие двух переменных и определяют знак корреляции (положительная или отрицательная). Если, например, между переменными существует сильная положительная взаимосвязь (увеличение одной переменной при увеличении второй), каждое слагаемое будет положительным числом. Аналогично, если между переменными существует сильная отрицательная взаимосвязь, все слагаемые в числителе будут отрицательными числами, что в результате дает отрицательное значение корреляции.
Знаменатель выражения для коэффициента парной корреляции [см. формулу (3.2.2)] просто нормирует числитель таким образом, что коэффициент корреляции оказывается легко интерпретируемым числом, не имеющим размерности, и принимает значения от -1 до +1.
Числитель выражения для коэффициента корреляции, который трудно интерпретировать из-за необычных единиц измерения, есть ковариация ХиУ. Несмотря на то что иногда она используется как самостоятельная характеристика (например, в теории финансов для описания совместного изменения курсов акций на двух биржах), удобнее пользоваться коэффициентом корреляции. Корреляция и ковариация представляют, по сути, одну и ту же информацию, однако корреляция представляет эту информацию в более удобной форме.
Для качественной оценки коэффициента корреляции применяются различные шкалы, наиболее часто - шкала Чеддока. В зависимости от значения коэффициента корреляции связь может иметь одну из оценок:
- 0,1-0,3 - слабая;
- 0,3-0,5 - заметная;
- 0,5-0,7 - умеренная;
- 0,7-0,9 - высокая;
- 0,9-1,0 - весьма высокая.
Оценка степени тесноты связи с помощью коэффициента корреляции проводится, как правило, на основе более или менее ограниченной информации об изучаемом явлении. В связи с этим возникает необходимость оценки существенности линейного коэффициента корреляции, дающая возможность распространить выводы по результатам выборки на генеральную совокупность.
Оценка значимости коэффициента корреляции при малых объемах выборки выполняется с использованием 7-критерия Стьюдента. При этом фактическое (наблюдаемое) значение этого критерия определяется по формуле

Вычисленное по этой формуле значение / набл сравнивается с критическим значением 7-критерия, которое берется из таблицы значений /-критерия Стьюдента (см. Приложение 2) с учетом заданного уровня значимости ос и числа степеней свободы (п - 2).
Если 7 набл > 7 табл, то полученное значение коэффициента корреляции признается значимым (т.е. нулевая гипотеза, утверждающая равенство нулю коэффициента корреляции, отвергается). И таким образом делается вывод, что между исследуемыми переменными есть тесная статистическая взаимосвязь.
Если значение г у х близко к нулю, связь между переменными слабая. Если корреляция между случайными величинами:
- положительная, то при возрастании одной случайной величины другая имеет тенденцию в среднем возрастать;
- отрицательная, то при возрастании одной случайной величины другая имеет тенденцию в среднем убывать. Удобным графическим средством анализа парных данных является диаграмма рассеяния , которая представляет каждое наблюдение в пространстве двух измерений, соответствующих двум факторам. Диаграмму рассеяния, на которой изображается совокупность значений двух признаков, называют еще корреляционным полем. Каждая точка этой диаграммы имеет координаты х (. и у г По мере того как возрастает сила линейной связи, точки на графике будут лежать более близко к прямой линии, а величина г будет ближе к единице.
Коэффициенты парной корреляции используются для измерения силы линейных связей различных пар признаков из их множества. Для множества признаков получают матрицу коэффициентов парной корреляции.
Пусть вся совокупность данных состоит из переменной Y = = (у р у 2 , ..., у п) и т переменных (факторов) X, каждая из которых содержит п наблюдений. Значения переменных Y и X, содержащиеся в наблюдаемой совокупности, записываются в таблицу (табл. 3.2.1).
Таблица 3.2.1
|
Переменная Номер наблюдения |
|||||
|
Х тЗ |
|||||
|
Х тп |
На основании данных, содержащихся в этой таблице, вычисляют матрицу коэффициентов парной корреляции R, она симметрична относительно главной диагонали:

Анализ матрицы коэффициентов парной корреляции используют при построении моделей множественной регрессии.
Одной корреляционной матрицей нельзя полностью описать зависимости между величинами. В связи с этим в многомерном корреляционном анализе рассматривается две задачи:
- 1. Определение тесноты связи одной случайной величины с совокупностью остальных величин, включенных в анализ.
- 2. Определение тесноты связи между двумя величинами при фиксировании или исключении влияния остальных величин.
Эти задачи решаются соответственно с помощью коэффициентов множественной и частной корреляции.
Решение первой задачи (определение тесноты связи одной случайной величины с совокупностью остальных величин, включенных в анализ) осуществляется с помощью выборочного коэффициента множественной корреляции по формуле

где R - R [см. формулу (3.2.6)]; Rjj - алгебраическое дополнение элемента той же матрицы R.
Квадрат коэффициента множественной корреляции Щ j 2 j _j J+l m принято называть выборочным множественным коэффициентом детерминации ; он показывает, какую долю вариации (случайного разброса) исследуемой величины Xj объясняет вариация остальных случайных величин Х { , Х 2 ,..., Х т.
Коэффициенты множественной корреляции и детерминации являются величинами положительными, принимающими значения в интервале от 0 до 1. При приближении коэффициента R 2 к единице можно сделать вывод о тесноте взаимосвязи случайных величин, но не о ее направлении. Коэффициент множественной корреляции может только увеличиваться, если в модель включать дополнительные переменные, и не увеличится, если исключать какие-либо из имеющихся признаков.
Проверка значимости коэффициента детерминации осуществляется путем сравнения расчетного значения /’-критерия Фишера

с табличным F
raбл. Табличное значение критерия (см. Приложение 1) определяется заданным уровнем значимости а и степенями свободы v l = mnv 2 = n-m-l.
Коэффициент R 2
значимо отличается от нуля, если выполняется неравенство

Если рассматриваемые случайные величины коррелируют друг с другом, то на величине коэффициента парной корреляции частично сказывается влияние других величин. В связи с этим возникает необходимость исследования частной корреляции между величинами при исключении влияния других случайных величин (одной или нескольких).
Выборочный частный коэффициент корреляции определяется по формуле

где R Jk , Rjj, R kk - алгебраические дополнения к соответствующим элементам матрицы R [см. формулу (3.2.6)].
Частный коэффициент корреляции, также как и парный коэффициент корреляции, изменяется от -1 до +1.
Выражение (3.2.9) при условии т = 3 будет иметь вид

Коэффициент г 12(3) называется коэффициентом корреляции между х { и х 2 при фиксированном х у Он симметричен относительно первичных индексов 1, 2. Его вторичный индекс 3 относится к фиксированной переменной.
Пример 3.2.1. Вычисление коэффициентов парной,
множественной и частной корреляции.
В табл. 3.2.2 представлена информация об объемах продаж и затратах на рекламу одной фирмы, а также индекс потребительских расходов за ряд текущих лет.
- 1. Построить диаграмму рассеяния (корреляционное поле) для переменных «объем продаж» и «индекс потребительских расходов».
- 2. Определить степень влияния индекса потребительских расходов на объем продаж (вычислить коэффициент парной корреляции).
- 3. Оценить значимость вычисленного коэффициента парной корреляции.
- 4. Построить матрицу коэффициентов парной корреляции по трем переменным.
- 5. Найти оценку множественного коэффициента корреляции.
- 6. Найти оценки коэффициентов частной корреляции.
1. В нашем примере диаграмма рассеяния имеет вид, приведенный на рис. 3.2.1. Вытянутость облака точек на диаграмме рассеяния вдоль наклонной прямой позволяет сделать предположение, что существует некоторая объективная тенденция прямой линейной связи между значениями переменных Х 2 Y (объем продаж).

Рис. 3.2.1.
2. Промежуточные расчеты при вычислении коэффициента корреляции между переменными Х 2 (индекс потребительских расходов) и Y (объем продаж) приведены в табл. 3.2.3.
Средние значения случайных величин Х 2 и Y, которые являются наиболее простыми показателями, характеризующими последовательности jCj, х 2 , ..., х 16 и y v y 2 , ..., у 16 , рассчитаем по следующим формулам:

|
Объем продаж Y, тыс. руб. |
Индекс потреби тельских расходов |
Объем продаж Y, тыс. руб. |
Индекс потреби тельских расходов |
||
Таблица 3.2.3
|
л:, - х |
(И - У)(х, - х) |
(х, - х) 2 |
(у,- - у) 2 |
||||
Дисперсия
характеризует степень разброса значений x v x 2 ,х :

Рассмотрим теперь решение примера 3.2.1 в Excel.
Чтобы вычислить корреляцию средствами Excel, можно воспользоваться функцией =коррел (), указав адреса двух столбцов чисел, как показано на рис. 3.2.2. Ответ помещен в D8 и равен 0,816.

Рис. 3.2.2.
(Примечание. Аргументы функции коррел должны быть числами или именами, массивами или ссылками, содержащими числа. Если аргумент, который является массивом или ссылкой, содержит текст, логические значения или пустые ячейки, то такие значения игнорируются; однако ячейки, которые содержат нулевые значения, учитываются.
Если массив! и массив2 имеют различное количество точек данных, то функция коррел возвращает значение ошибки #н/д.
Если массив1 либо массив2 пуст или если о (стандартное отклонение) их значений равно нулю, то функция коррел возвращает значение ошибки #дел/0 !.)
Критическое значение /-статистики Стьюдента может быть также получено с помощью функции стьюдраспробр 1 пакета Excel. В качестве аргументов функции необходимо задать число степеней свободы, равное п - 2 (в нашем примере 16 - 2= 14) и уровень значимости а (в нашем примере а = 0,1) (рис. 3.2.3). Если фактическое значение /-статистики, взятое по модулю, больше критического, то с вероятностью (1 - а) коэффициент корреляции значимо отличается от нуля.

Рис. 3.2.3. Критическое значение /-статистики равно 1,7613
В Excel входит набор средств анализа данных (так называемый пакет анализа), предназначенный для решения различных статистических задач. Для вычисления матрицы коэффициентов парной корреляции R следует воспользоваться инструментом Корреляция (рис. 3.2.4) и установить параметры анализа в соответствующем диалоговом окне. Ответ будет помещен на новый рабочий лист (рис. 3.2.5).
1 В Excel 2010 название функции стьюдраспробр изменено на стью-
ДЕНТ.ОБР.2Х.

Рис. 3.2.4.

Рис. 3.2.5.
- Основоположниками теории корреляции считаются английские статистики Ф. Гальтон (1822-1911) и К. Пирсон (1857-1936). Термин «корреляция» был заимствован из естествознания и обозначает «соотношение, соответствие». Представление о корреляции как взаимозависимости между случайными переменными величинами лежит воснове математико-статистической теории корреляции.
Онлайн калькуляторы